2019年/11月/18日
两个Facade
我们的系统,应该源源不断的把日志流进日志聚合平台,比如ELK,把度量数据流进时间序列存储,比如InfluxDB, 这样我们才能通过度量预警问题,通过日志查找证据
于是IT界在这两个领域搞出来了五花八门的技术组件
日志就有这么多:
Jdk Logger
Log4j
Log4j2
Lobback
Apache Commons Logging
Tinylog
SLF4j
度量监控有这么多:
AppOptics
Azure Monitor
Netflix Atlas
CloudWatch
Datadog
Dynatrace
Elastic
Ganglia
Graphite
Humio
Influx/Telegraf
JMX
KairosDB
New Relic
Prometheus
SignalFx
Google Stackdriver
StatsD
Wavefront.
你应该怎么选择呢?
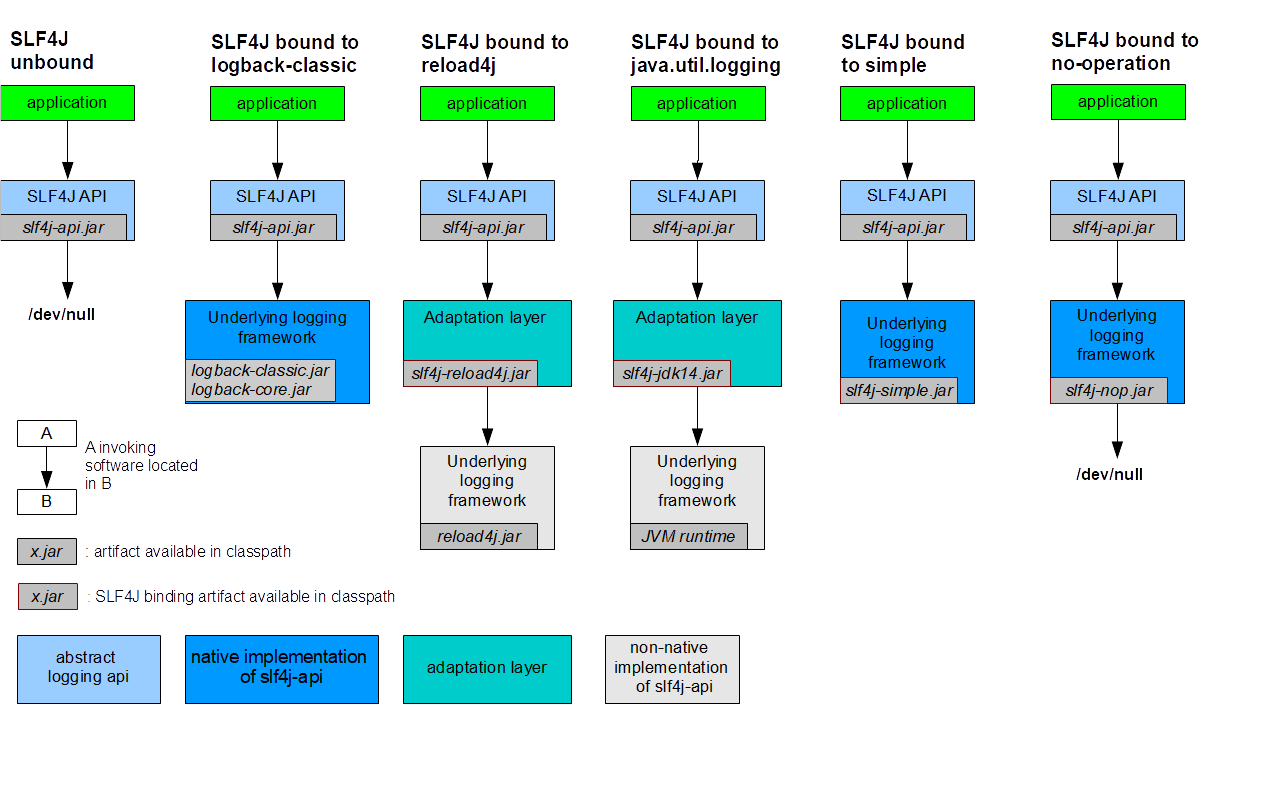
答案是SLF4j和Micrometer,他们都是两个门面,底层通过SPI来适配各种实现,这样让你的上层代码不变,底层随便切换
The Simple Logging Facade for Java (SLF4J) serves as a simple facade or abstraction for various logging frameworks (e.g. java.util.logging, logback, log4j) allowing the end user to plug in the desired logging framework at deployment time.
Micrometer provides a simple facade over the instrumentation clients for the most popular monitoring systems, allowing you to instrument your JVM-based application code without vendor lock-in. Think SLF4J, but for metrics.
对于SLF4j,你始终应该选择logback-classic, 因为他们是深度集成和优化的
NATIVE IMPLEMENTATION There are also SLF4J bindings external to the SLF4J project,
e.g. logback which implements SLF4J natively.
Logback's ch.qos.logback.classic.Logger class is a direct implementation of SLF4J's org.slf4j.Logger interface.
Thus, using SLF4J in conjunction with logback involves strictly zero memory and computational overhead.
我们所熟悉的Spring框架,历史是上一直都是使用Apache Commons Logging,到了5.0直接把它打包到了一起,剔除了很多类,只保留对其他日志实现的查找逻辑
而对于Micrometer,我推荐的是prometheus,因为它是Google血统,和现在几乎要统一天下的Kubernetes配合得极致顺滑,再加上Go语言实现出来的极简安装体验.
